前排提示:多图预警。
目前我已经完整部署了GLM4-9B,也就是GLM-4的普通对话版本,可以理解为一个基础的聊天机器人。不过说是基础,也只是相对于完全体而言,实际功能相较于其他开源大模型和上一代的GLM3来说可谓是“遥遥领先”,称得上是10B规模以下的最强大模型。以下就是详细的体验分享了。
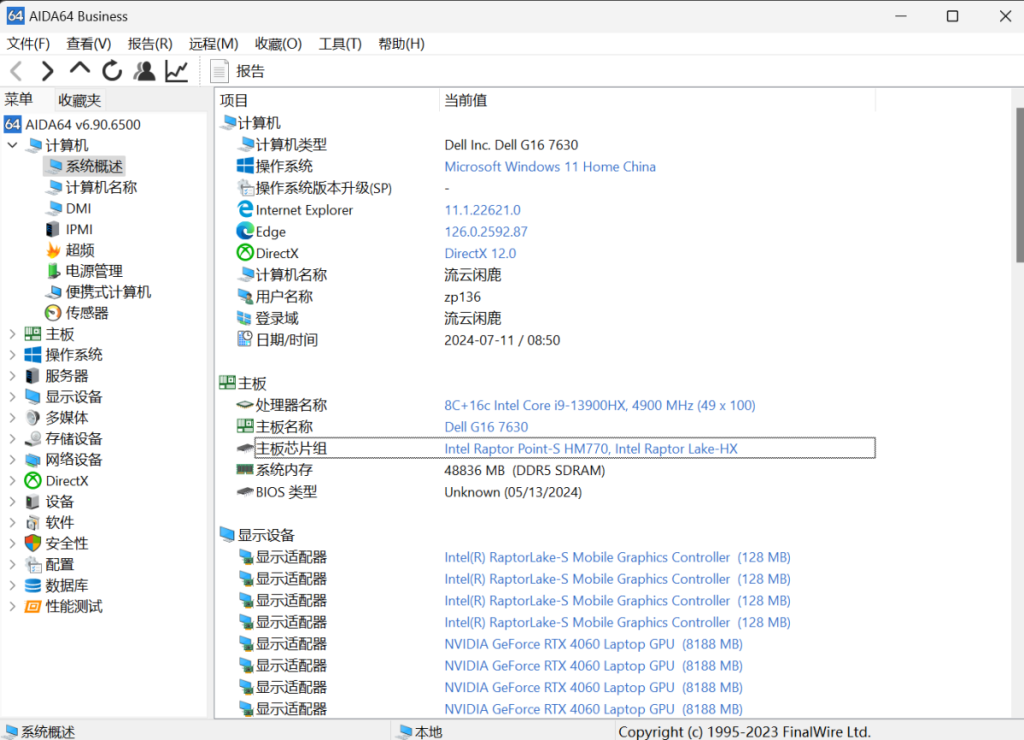
硬件要求方面,相较于前代,GLM-4对于硬件的要求大大提高,官方最低显存要求提升到了16G,在强制使用int4量精度下初始显存占用提升到了近7个G,也就意味着想要在本地部署使用至少显存需要8G。
在加载模型时也会有很大的内存消耗,不过目前来看并不是硬性条件。但是一颗性能强悍的处理器和25G以上的内存无疑会大大提升模型的加载速度。
在GLM-3上尝试过的双开在GLM-4中我也进行了测试,但是遗憾的是由于显卡显存不足,第二个程序无法加载。
GLM-4本体的体量相对于前代的35G也有了一轮暴涨,提升到了整整50G,使得我本就紧张的储存空间更加的不堪重负。
综上,想要愉快的玩耍GLM-4,显存需要至少8G,最好22G以上,空余内存最好有20G以上,硬盘空间50G以上。
接下来是使用体验,GLM-4本次开源的主要功能包括了常规聊天,文档解读,图像识别。在这三个功能中我尝试了常规聊天和多模态图像识别,总体体验极佳。而文档解读功能由于未知问题仍然无法使用,但我会对此进行简短介绍。
首先是常规的聊天,本次测试我选用了传说中用于训练效果最好的,也是集中文社区语言艺术大成的百度贴吧弱智吧中的部分问题进行测试。
第一张图为GLM-4回答,第二张图为GLM-3回答。
第一个问题:回忆算不算在记忆的长河里刻舟求剑?
第二个问题:解释一下“一个半小时就是三个半小时”的意思。
第三个问题:解释一下“太空有空间站,太挤没有空间站”的意思。
第四个问题:房东把房租给我,为什么不把房租给我?
第五个问题:高考满分才750,怎么才能考985?
可以看出GLM-4对于GLM-3还是有不小提升,在对文字逻辑的处理方面更加敏锐。并且,GLM-4还支持联网搜索功能,但是具体操作略有繁琐,并且还需要进行付费,暂且按下不表。
GLM-4初始模型具备长文本解读能力,很好的一点就是支持的文件格式非常的多样化,从常规的txt,docx,到PDF,GLM-4都可以对其进行解读,极大的便利了有大量长文本阅读需求的用户。
目前我的问题仍然不能确定,正在Github上进行探讨研究。
GLM-4系列开源了ChatGLM-4v-9B视觉模型,这也是GLM系列首个机器视觉模型,登场即为王炸。得益于ChatGLM4强大的中文理解能力,ChatGLM-4v-9B在用出色图文识别的基础上可以理解复杂指令,通过更为高效的训练方式使其在参数量较低的情况下发挥出更好的表现。
由于我的硬件限制,这个多模态功能并没有那么实用,主要问题是显卡的性能过于孱弱,在第一次尝试的时候就出现了报错。
在询问了B站大佬并翻找万能评论区得到了解决方案,需要更改模型文件中的一个响应时间值。官方给出的值仅为5,但是由于部署的硬件条件参差不齐,有一些显卡性能较差的用户(比如我)无法达到那么快的响应速度导致报错。
在经过几次尝试后我将响应时间值改为了300(红线部分),终于是可以正常使用了,不过反馈时间就很长,提问后往往要数分钟才能得到回答,但是胜在结果的高质量,用起来倒也挺舒服。
目前我只开发了基本的图像识别功能,不能说极为出色,但也是主流水平。
在B站的GLM官方给出了另一个打开方式,网页截图翻译HTML代码,我截了一张网页的首页进行尝试,结果看起来还不错。
好啦,基本可分享的就这么多,感兴趣的可以前往B站搜索up主十字鱼的视频下载。
引用: GLM4官方Github文档 https://github.com/THUDM/GLM-4/tree/main 出处:Github
鉴于up主只上传123云盘(非VIP下载要掏钱)并且没有把GLM4的文件单独列出,我把自己已经调整好的文件夹打包了一下上传了百度网盘,主要调整的有自适应代码量化方式和上文提到的模型响应时间值。如需下载请保证硬盘至少有50G空间。
引用: 百度网盘链接: https://pan.baidu.com/s/1xbHnPCe0OmrfnVOgQOddgA 提取码: lyxl
插入一个不算题外话的题外话,得益于GLM4得到提升的中文识别记忆能力,许多人从四年前就开始追求的赛博猫娘已经可以真正意义上的国产化,本地化了(大喜)。对此感兴趣的大伙也可以通过评论区或邮箱一起交流。

发表回复